Supercharging Research Paper Insights with Trigger.dev, Sequin, Neon, and Pinecone
Explore how FlatUniverse uses modern tools like Trigger.dev, Sequin, Neon, and Pinecone to transform research paper processing. This article dives into the technical architecture and workflows that make research papers accessible, from metadata extraction and vector embedding to AI-driven semantic search.
Series: Building the Flatuniverse app
- Supercharging Research Paper Insights with Trigger.dev, Sequin, Neon, and Pinecone
- Intelligent Paper Search: Implementing Time-Aware AI Responses in Flatuniverse
Over the past few months, I've developed an app that makes research papers more understandable for humans: https://www.flatuniverse.app/. The app processes research papers and uses powerful search tools and AI to help users discover relevant papers. In this article, I'll explain the process that prepares papers for the app. Since the app is open source, you can explore additional details and components not covered here.
You can find the code repo here.
Overview
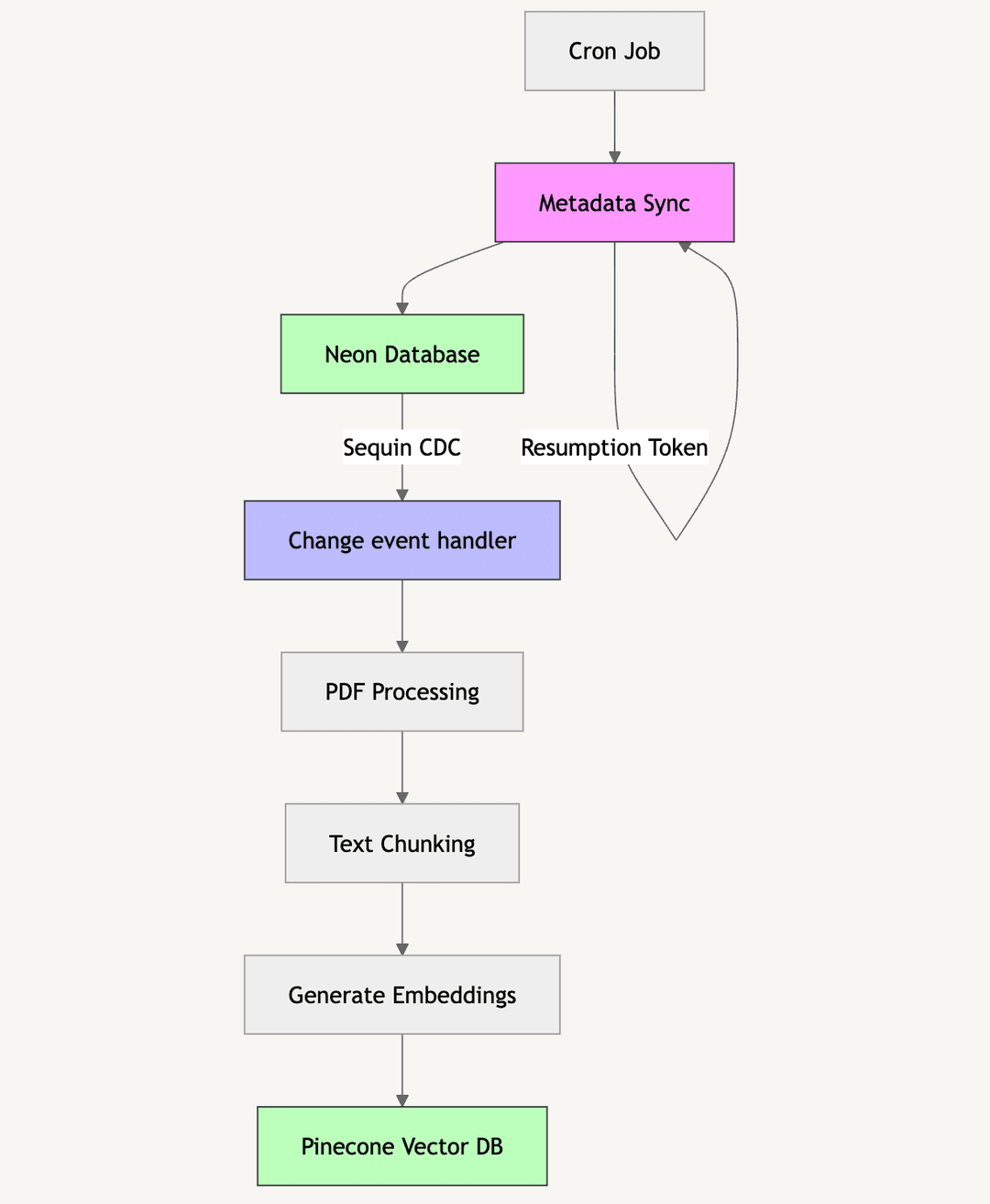
Importing and processing research papers follows an asynchronous flow triggered by a cron job. The process involves several steps, from initial scheduling to data storage. Let's review these steps before diving deeper into the technical details and source code in the following sections:
- A scheduler initiates the process at regular intervals
- Fetch the XML formatted article metadata
- Parse the XML data and transform it into a JSON object
- Save the parsed metadata objects to a database in batches
- The successful database save triggers the next processing step
- Fetch the PDF content of the research paper
- Generate embeddings from processed paper content
- Save the generated embeddings to a vector database
Once complete, we have both the research paper metadata in our database and the generated embeddings stored in a vector database.
The core components of the application include:
- Next.js: A React framework for building server-side rendered and statically generated web applications.
- Trigger.dev: A platform for building and managing background jobs and workflows.
- Neon: A serverless Postgres database for storing structured data.
- Pinecone: A vector database for storing and searching high-dimensional vectors, ideal for semantic search and AI applications.
- Sequin: Replace clunky tools like Debezium by streaming data from Postgres to SQS, Kafka, and more.
- LlamaIndex: LlamaIndex is a framework for building LLM-powered applications. LlamaIndex helps you ingest, structure, and access private or domain-specific data.
Scheduler
For task scheduling, the app uses the trigger.dev platform to deploy NodeJS functions as tasks and schedule cron jobs to initiate them. The tasks are highly flexible, they can call each other in various ways and perform any operation supported by the NodeJS runtime in a deployed environment.
The cron job in this example calls the researchSync task in every 6 hours.
/**
* Schedule configuration for the research sync task.
* This schedule runs every 6 hours to fetch and sync new research metadata.
*
* @remarks
* - Uses cron expression to run at minute 0 past every 6th hour
* - Includes deduplication to prevent multiple concurrent runs
* - Generates unique externalId for each scheduled run
*/
export const researchSyncSchedule = schedules.create({
task: researchSync.id,
externalId: randomUUID(),
deduplicationKey: "research-sync-scheduler",
// At minute 0 past every 6th hour
cron: "0 */6 * * *",
});Fetching the XML formatted article metadata
The app integrates with https://arxiv.org/ through its convenient API. The metadata fetching happens through a trigger.dev task, which is called by the researchSync task mentioned earlier. This task needs a startDate parameter to determine which research papers to fetch. The app fetches papers from the current day several times daily, ensuring continuous updates to the system. I don't want to dig deep into the arXiv API but I mention two important parts which can be considered as general rules of integrating with third-party APIs.
- Pagination: especially if you plan to use large data set, be prepared to fetch the data paginated from the external source. arXiv API uses resumption token to control the data.
- Retry: if your service builds heavily on third party API requests, it worth to build some kind of retry mechanism to give a chance to recover after a failed request. The request can fail due many reason that a retry can solve, e.g network issue, server timeout, rate limit error, etc. Make sure you apply exponential backoff (or some sort of increasing timout) to give some time to the external server to recover.
Trigger.dev gives several options to configure retries for you tasks or requests if you want to retry only a specific request in a task after a failure.
const responseTextData = await retry.onThrow(
async ({ attempt }) => {
...
const response = await fetch(initialRequestUrl, { cache: 'no-store' });
if (response.status === 503) {
const retryAfter = response.headers.get('retry-after');
await wait.for({ seconds: getRetrySeconds(retryAfter) });
throw new Error(`Metadata fetch failed with status code 503 on attempt ${attempt}`);
}
...
},
{ maxAttempts: 3, randomize: false }
);Data Storage in the app: A Dual Database Approach
In the Flatuniverse app, efficient data storage is important for handling the vast amount of research papers processed daily. To achieve this, the application uses a dual database strategy with Neon and Pinecone. This approach allows the application to uses the strengths of each database, optimizing for both structured and unstructured data storage.
Neon: The Backbone for Structured Data
Neon serves as the primary database for storing structured data within the app. This includes metadata about research papers, such as titles, authors, categories, publication dates, and abstracts.
Key Features of Neon:
- Relational Database: As a serverless Postgres database, Neon is ideal for managing structured data with complex relationships. It supports SQL queries, making data retrieval and manipulation straightforward and efficient.
- Scalability: Neon’s serverless architecture allows it to automatically scale based on demand, ensuring that the application can handle varying loads without performance degradation.
- Data Integrity: With built-in support for transactions and constraints, Neon ensures that data remains consistent and reliable, which is essential for maintaining accurate metadata records.
Pinecone: Semantic Search with Vector Data
While Neon handles structured data, Pinecone is used for storing high-dimensional vectors, such as embeddings generated from PDFs. These embeddings are crucial for the application's AI-driven features, like semantic search and similar article recommendations.
Key Features of Pinecone:
- Vector Database: Pinecone is specifically designed for storing and querying vector data, which is common in AI applications. It is great at handling high-dimensional data efficiently.
- Semantic Search: By storing embeddings, Pinecone enables the application to perform semantic searches, allowing users to find similar articles based on content rather than just keywords. This enhances the user experience by providing more relevant search results.
- Performance: Pinecone is optimized for fast retrieval of vector data, making it ideal for applications that require real-time or near-real-time search capabilities.
The app saves embeddings for each page of the paper to be able to retrieve more precise suggestions. The unique id strategy is to combine the metadataId and the index of the given page, so we can easily get the pages of a research paper but the app also can retrieve an exact page of a paper as an answer or suggestion.
export const createPineconeId = (...ids: (string | number)[]) => `${ids.join('#')}`;
/**
* Adds vectors and their associated document metadata to the vector store index.
*
* @param {TextNode<T>[]} nodes - An array of documents containing metadata for each vector.
* @param {Index<RecordMetadata>} [vectorStoreIndex=researchArticleIndex] - The vector store index to update (default is researchArticleIndex).
* @returns {Promise<void>} A promise that resolves when the upsert operation is complete.
*/
export const addVectorsToIndex = async <T extends Metadata>(
nodes: TextNode<T>[],
vectorStoreIndex: Index<RecordMetadata> = researchArticleIndex
): Promise<void> =>
vectorStoreIndex.upsert(
nodes.map((node, idx) => {
return {
id: createPineconeId(node.metadata.metadata_id, idx),
values: node.getEmbedding(),
metadata: node.metadata,
};
})
);Why a Dual Database Approach?
The decision to use both Neon and Pinecone is driven by the need to handle different types of data efficiently:
- Structured vs. Unstructured Data: Neon is well-suited for structured data with defined schemas, while Pinecone is optimized for unstructured, high-dimensional vector data.
- Specialized Capabilities: Each database offers specialized capabilities that enhance the application's functionality. Neon provides robust relational data management, while Pinecone offers advanced vector search capabilities.
- Performance Optimization: By using the strengths of each database, the app can optimize performance for both metadata management and AI-driven search features.
Generating Embeddings Using LlamaIndex and OpenAI
The embedding generation process is a crucial step in making research papers searchable and understandable through AI. LlamaIndex provides powerful tools for processing and structuring the PDF content, while OpenAI's embedding models transform this content into high-dimensional vectors that capture semantic meaning. This combination enables advanced search capabilities and content understanding that goes beyond simple keyword matching.
/**
* OpenAI embeddings instance configured with text-embedding-3-small model
* and cosine similarity comparison function.
*
* Cosine similarity measures the similarity between two vectors by calculating
* the cosine of the angle between them. The result ranges from -1 to 1, where:
* - 1 means the vectors are identical
* - 0 means they are perpendicular (completely different)
* - -1 means they are opposite
*
* Used to generate embeddings for PDF text chunks and compare their semantic
* similarity by measuring the cosine angle between their vector representations.
*/
const openAIEmbeddings = new OpenAIEmbedding({
model: 'text-embedding-3-small',
similarity: (a, b) => {
return cosineSimilarity(a, b);
},
});
/**
* Loads a PDF file from a URL, splits it into text chunks, and generates embeddings.
*
* @param pdfPath - The URL path to the PDF file to load
* @param metadata - Additional metadata to attach to each text node
* @returns An array of TextNodes containing the chunked text and embeddings
*
* The function:
* 1. Creates a sentence splitter to chunk the text
* 2. Loads and extracts text from the PDF
* 3. Splits the text into nodes
* 4. Generates embeddings for each node
* 5. Returns TextNodes with the text, embeddings and metadata
*/
export const loadPDF = async (pdfPath: string, metadata: Metadata): Promise<TextNode<Metadata>[]> => {
const splitter = new SentenceSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const docs = await getDocumentsFromPDF(pdfPath);
const nodes = splitter.getNodesFromDocuments(docs);
return Promise.all(
nodes.map(async (node) => {
const embeddings = await openAIEmbeddings.getTextEmbeddingsBatch(splitter.splitText(node.text));
return new TextNode({
...node,
embedding: embeddings[0],
metadata: {
...node.metadata,
...metadata,
},
});
})
);
};Asynchronous data processing
The steps of processing research papers in the app are designed to run asynchronously, allowing for efficient handling of large volumes of data. This approach ensures that resource-intensive tasks like PDF processing and embedding generation don't block the main application flow and can happen not only asynchronous but parallel. The system uses trigger.dev's job scheduling and Sequin streaming capabilities to coordinate these operations, making the entire pipeline robust and scalable.
Trigger.dev task trigger
A major advantage of trigger.dev tasks are that you can trigger them from other tasks or your backend code without waiting for their completion. The trigger.dev platform provides comprehensive monitoring and tracing for all tasks, making it easy to track their progress and results.
Example: Paginated metadata sync
In the Flatuniverse app, research article metadata is fetched using asynchronous task triggers based on a resumption token. The synchronization process runs as a trigger.dev task that can be initiated by other tasks or any Node.js code. The process works similarly to a recursive method, where the synchronization task triggers itself. However, since each new trigger is asynchronous, the previous task is completed immediately after triggering the next one, rather than waiting for it to finish.
export const syncMetadata = task({
id: 'metadata-sync',
run: async (_payload: ResearchSyncPayload) => {
...
if (token) {
// send the resumption token to the same event
// no need to wait for the result
await syncMetadata.trigger(
{
jobId: payload.jobId,
startDate: payload.startDate,
untilDate: payload.untilDate,
resumptionToken: token,
},
{
idempotencyKey: `sync-metadata-${payload.jobId}-${payload.startDate}-${payload.untilDate}`,
}
);
}
},
});Sequin change data capture
Sequin's change data capture (CDC) capabilities play a crucial role in maintaining data consistency across the application. By monitoring changes in the Neon database, Sequin enables real-time synchronization of data modifications, ensuring that any updates to research paper metadata are promptly reflected throughout the system. This streaming approach allows for efficient handling of database changes without the need for periodic polling or batch updates.
Example: Generating AI Content
One of the key tasks in the application is generating AI content from research papers. The process first checks whether embeddings exist for a given article. If they don't, it triggers the generation of embeddings from the PDF. While a trigger.dev task handles the actual generation, Sequin's database change stream initiates the AI content generation process. This approach ensures that metadata is saved to the Neon database first, allowing article pages to display new metadata even if AI content generation fails. Since Sequin persists the streamed events, failed AI generation attempts can be replayed at any time.
/**
* Handles webhook events for metadata changes from Sequin.
* This endpoint is called when article metadata is inserted or updated in the database.
*
* @param req - The incoming HTTP request
* @returns NextResponse with success/error status
*
* Flow:
* 1. Validate the webhook secret in Authorization header
* 2. Parse and validate the payload using metadataChangeEventSchema
* 3. For insert actions:
* - Trigger the generate-ai-content task to create embeddings and AI content
* - Return success response
* 4. For other actions:
* - Return 304 Not Modified
*/
const handleMetadataChangeEvent = async (req: Request) => {
const authHeader = req.headers.get('Authorization');
if (!authHeader || authHeader !== `${process.env.SEQUIN_WEBHOOK_SECRET}`) {
return NextResponse.json({ error: 'Unauthorized' }, { status: 401 });
}
...
if (metadataChangeEvent.data.action === 'insert') {
const handle = await tasks.trigger<typeof generateAIContent>('generate-ai-content', {
jobId: metadataChangeEvent.data.record.id,
data: [
{
articleMetadataId: metadataChangeEvent.data.record.id,
externalId: metadataChangeEvent.data.record.external_id,
},
],
});
return NextResponse.json({ success: true });
}
return NextResponse.json({ success: true, status: 304 });
};
export const POST = handleMetadataChangeEvent;Error Handling and System Resilience
A robust error handling strategy is crucial for maintaining system reliability in an asynchronous processing pipeline. The application implements several layers of error handling and resilience mechanisms to ensure smooth operation even when issues arise.
Retry Mechanisms
The system employs automatic retry logic for failed operations, particularly in critical processes like PDF processing and embedding generation. trigger.dev's built-in retry capabilities are used to handle temporary failures in external service calls and network issues.
export const processDocument = task({
id: "process-document",
retry: {
maxAttempts: 3,
backoff: {
type: "exponential",
minSeconds: 30,
},
},
run: async (payload) => {
// Processing logic here
},
});Monitoring and Alerting
Comprehensive error tracking and monitoring are implemented across the processing pipeline. This includes:
- Real-time error notifications through trigger.dev's monitoring system
- Detailed error logging with contextual information for debugging
- Performance metrics tracking to identify potential bottlenecks
- Automated alerts for critical failures requiring immediate attention
Data Consistency
The system maintains data consistency through transaction management and idempotent operations. Sequin's CDC capabilities help ensure that data remains synchronized even when processing steps fail and need to be retried.
These resilience mechanisms work together to create a robust system that can handle failures gracefully while maintaining data integrity and system availability.
Final thoughts
Building a system to process and analyze research papers requires careful consideration of various technical components and their interactions. The combination of trigger.dev for task orchestration, Sequin for data synchronization, Neon for structured data storage, and Pinecone for vector search creates a robust and scalable architecture. This approach not only ensures efficient processing of research papers but also provides a foundation for future enhancements and scaling of the application.
The modular design and use of modern cloud services also makes it easier to iterate and improve individual components without disrupting the entire system. As the field of AI and research paper processing continues to evolve, this architecture provides the flexibility needed to incorporate new capabilities and technologies. The open-source nature of the project invites collaboration and enables others to build upon and enhance these foundations.
If you are interested in learning more about how this architecture works in practice, you can explore the open-source codebase on GitHub.
Or explore the capability of the app firsthand by visiting Flat Universe at https://www.flatuniverse.app. The platform provides an intuitive interface for exploring and understanding research papers through AI-powered features. Whether you're a researcher, student, or just curious about scientific literature, Flat Universe offers tools to make academic papers more accessible and comprehensible.