Building a knowledge base AI app with Python, LlamaIndex and ChromaDB
One of the best use cases of AI and RAG is to extract information from large amounts of data. In this article, we build a simple web app that allows us to upload documents and ask questions about the uploaded documents.
RAG stands for Retrieval-Augmented Generation, a technique that combines information retrieval with language generation. It enhances AI models by allowing them to access and incorporate external knowledge when generating responses, improving accuracy and relevance. In our context, RAG enables the app to retrieve relevant information from uploaded documents to answer user queries.
This approach not only enhances the AI’s ability to provide accurate and contextually relevant answers but also allows for a more dynamic and interactive user experience. By using RAG, our application can effectively bridge the gap between the vast amount of information contained in uploaded documents and the specific queries posed by users, resulting in a more intelligent and responsive knowledge base system.
You can find the code repo for this article here:
https://github.com/dobosmarton/document-rag-app
Prerequisites
You need to have installed Python and Poetry on your machine.
Poetry is a dependency management and packaging tool for Python that simplifies the process of creating and managing Python projects. It allows developers to declare and manage project dependencies, using a pyproject.toml file. Poetry handles virtual environments automatically, ensuring that dependencies are isolated and consistent across different environments.
You also need an OpenAI account to generate an API key. When you have that, create a .env file based on the .env.example and paste the key there. The Minio bucket name and keys can be generated once you start Minio based on the docker-compose file in the next section.
Running the project
This is a local setup so I added a docker-compose file to run the necessary components locally. The project uses Minio to store the uploaded files and ChromaDB to store embeddings and indexes. For ChromaDB we use server mode, enabling us to communicate with the DB via HTTP requests.
This setup allows for efficient storage and retrieval of both raw documents and their vector representations. The docker-compose file defines the services for ChromaDB and Minio, specifying the necessary configurations for each. ChromaDB is exposed on port 8000, while Minio uses ports 9000 and 9001. Both services are configured with persistent storage volumes to ensure data retention across container restarts.
services:
chromadb:
image: ghcr.io/chroma-core/chroma:latest # Use the latest ChromaDB image
container_name: chromadb
ports:
- "8000:8000" # Expose the ChromaDB API on port 8000
environment:
- CHROMA_DB_PATH=/data/chroma
volumes:
- chromadb_data:/data/chroma # Persistent storage for the ChromaDB database
minio:
image: docker.io/bitnami/minio:latest
ports:
- "9000:9000"
- "9001:9001"
networks:
- minionetwork
volumes:
- "minio_data:/data"
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=admin1234
- MINIO_DEFAULT_BUCKETS=datasource
networks:
minionetwork:
driver: bridge
volumes:
minio_data:
driver: local
chromadb_data:
driver: localAs the next step, install the packages defined in the pyproject.toml file. We use Poetry to manage dependencies, so you can use the following command to install the packages.
poetry installNow you need only two more commands to start the app locally.
poetry shell
uvicorn document_rag:app — reloadYou can use the reload flag if you want to modify the code, so the app will reload every time you change something in the codebase. If you see these messages in your terminal then everything is fine, you can use the API to upload some documents.

The easiest way to test the API is using Curl, Postman, or something similar tool.
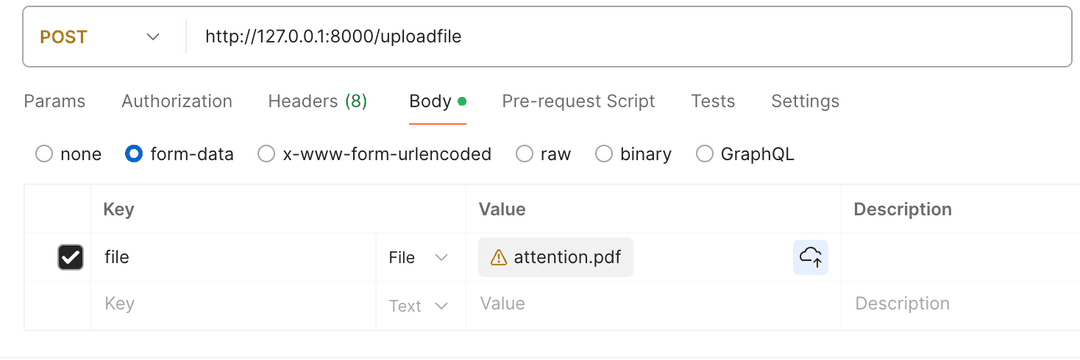
You can validate the result by opening the Minio web interface and checking the uploaded file in the right bucket. After a successful file upload, you can finally unlock the model’s intelligence and ask questions.
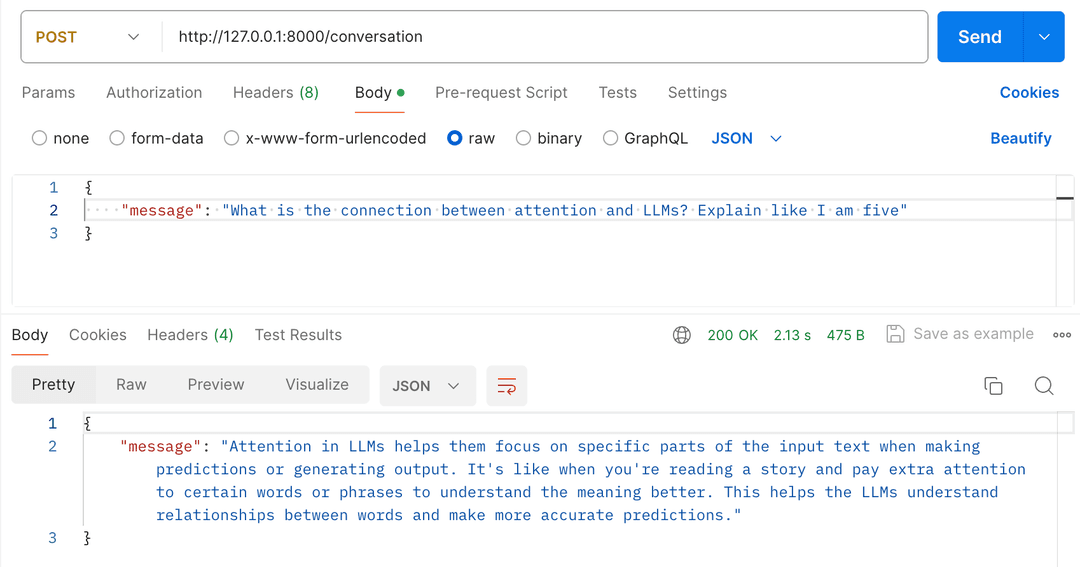
Code review
Let’s review some parts of the code base to understand how the app works.
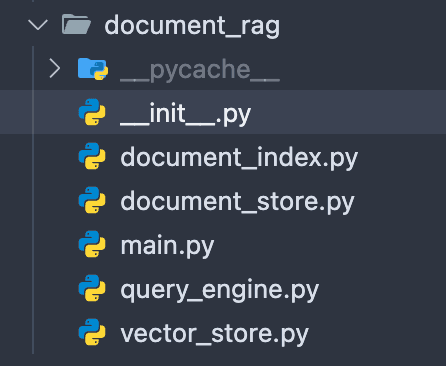
The project has a simple flat file structure. This is a simple app, we don’t want to overcomplicate things.
API handlers
The main.py file stores the FastAPI routes and a document index context. It is dependable that we can inject into our routes to provide access to the document index.
def get_document_index_context():
try:
yield get_document_index()
except Exception as e:
raise HTTPException(status_code=500, detail=f"Document index error: {e}")FastAPI handles the dependency resolution, calls the function, and passes the yield value as a function parameter allowing the handler to use the document index, as you can see in the conversation endpoint.
@app.post("/conversation", response_model=ConversationPayload)
async def conversation(
payload: ConversationPayload,
document_index: Annotated[VectorStoreIndex, Depends(get_document_index_context)],
) -> ConversationPayload:
try:
response = query(payload.message, document_index)
return ConversationPayload(message=response)
except Exception as e:
print("Error processing the request", e)
raise HTTPException(status_code=400, detail="Error processing the request")The document index is a VectorStoreIndex from LlamaIndex.
Vector Stores are a key component of retrieval-augmented generation (RAG) and so you will end up using them in nearly every application you make using LlamaIndex, either directly or indirectly.
This is the heart of our AI application. We add the uploaded file data to the index and we use it to retrieve the answers to the questions coming from the conversation requests.
The index serves as a powerful tool for efficiently retrieving relevant information from the uploaded documents. By using the vector representations of the text, we can perform semantic searches that go beyond simple keyword matching. This allows our application to understand the context and meaning behind user queries, resulting in more accurate and insightful responses.
Document and Vector stores
Our two types of data stores serve different needs. When you upload a file, we store it immediately in Minio. This ensures that if we later need to rebuild the index from scratch, we have all the necessary resources. Minio is an S3-compatible document store, which means if you want to deploy the application to the cloud, you can easily switch from Minio to S3.
client = Minio(
endpoint=bucket_endpoint,
access_key=bucket_access_key,
secret_key=bucket_secret_key,
secure=False,
)
def get_storage_client() -> AsyncFileSystem:
s3 = core.S3FileSystem(
key=bucket_access_key,
secret=bucket_secret_key,
endpoint_url=bucket_endpoint_url,
)
if not s3.exists(bucket_name):
s3.mkdir(bucket_name)
return s3
def upload_file(file: UploadFile, object_name: str) -> ObjectWriteResult:
assert client.bucket_exists(bucket_name)
try:
result = client.put_object(
bucket_name=bucket_name,
object_name=object_name,
data=file.file,
length=file.size,
content_type=file.content_type,
)
return result
except Exception as e:
return f"Error uploading file: {e}"Transforming the text files to embedding vectors is a key part of a RAG application. We store these vectors in ChromaDB, an open-source vector database.
ChromaDB is designed to store and query vector embeddings, making it an ideal choice for our RAG application. By using ChromaDB, we can efficiently store and retrieve the vector representations of our documents, enabling fast and accurate semantic searches. This allows our application to quickly find the most relevant information when responding to user queries, significantly enhancing the overall performance and user experience.
chroma_host = os.getenv("CHROMA_HOST")
chroma_port = os.getenv("CHROMA_PORT")
singleton_vector_store = None
def get_vector_store_singleton() -> VectorStore:
global singleton_vector_store
if singleton_vector_store is not None:
return singleton_vector_store
chroma_client = chromadb.HttpClient(
host=chroma_host,
port=chroma_port,
settings=Settings(
allow_reset=True,
anonymized_telemetry=False,
),
)
# create client and a new collection
chroma_collection = chroma_client.get_or_create_collection("documents")
singleton_vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
return singleton_vector_storeStorage context
The storage context is a LlamaIndex utility container for storing nodes, indices, and vectors. Using storage context makes it easier to run queries against the ML model. We persist the context in our S3-compatible Minio storage.
This allows us to efficiently retrieve and update the stored information as needed. The storage context plays a crucial role in maintaining the persistence of our document index across different sessions, ensuring that we can quickly access and utilize previously processed data without having to rebuild the entire index from scratch.
def get_or_create_storage_context(
vector_store: VectorStore,
fs: Optional[AsyncFileSystem] = None,
) -> StorageContext:
try:
return StorageContext.from_defaults(
persist_dir=index_persist_dir, vector_store=vector_store, fs=fs
)
except ValueError:
print("Could not find storage context in S3. Creating new storage context.")
storage_context = StorageContext.from_defaults(vector_store=vector_store, fs=fs)
storage_context.persist(persist_dir=index_persist_dir, fs=fs)
return storage_context
Document index
As the last part of the application, let’s review the index generation and index manipulation logic. The get_document_index function retrieves or creates a VectorStoreIndex, which is the core component for storing and querying our document embeddings. It uses the storage context and vector store we set up earlier.
The add_document function is responsible for processing new documents and adding them to our index. It reads the document from our S3-compatible storage, parses it into nodes, and inserts these nodes into the index.
Finally, the query function allows us to perform searches against our indexed documents, using the power of the VectorStoreIndex to find relevant information based on the user's query.
openai.api_key = os.getenv("OPENAI_API_KEY")
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
def get_document_index() -> VectorStoreIndex:
document_fs = get_storage_client()
vector_store = get_vector_store_singleton()
storage_context = get_or_create_storage_context(
vector_store,
fs=document_fs,
)
return VectorStoreIndex.from_vector_store(
storage_context=storage_context,
vector_store=vector_store,
embed_model=embed_model,
)
def add_document(
document_location: str,
bucket_name: str,
index: VectorStoreIndex | None = None,
) -> None:
file_system = get_storage_client()
documents = SimpleDirectoryReader(
input_dir=bucket_name, input_files=[document_location]
).load_data(fs=file_system)
parsed_nodes = SimpleFileNodeParser().get_nodes_from_documents(documents=documents)
index.insert_nodes(nodes=parsed_nodes)
def query(
query_payload: str,
index: VectorStoreIndex,
) -> str:
response = index.as_query_engine().query(query_payload)
return response.responseFinal thoughts
This simple RAG application demonstrates the power of combining document storage, vector embeddings, and natural language processing to create a question-answering system. By using tools like LlamaIndex, ChromaDB, and Minio, we’ve built a flexible solution that can be easily adapted for various use cases. You can easily extend the general knowledge base with your private documents without publishing sensitive data online. As AI technologies continue to evolve, applications like this will become increasingly valuable for extracting insights from large volumes of unstructured data.